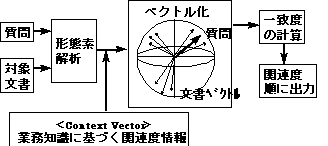
 図3. システム構成
図3. システム構成98-5-15
本システムは、全く新しいコンセプトに基づいて、文書情報処理に必要な知識を自動学習する知的システムであり、概念的な検索・分類機能を実現すると共に、その結果をビジュアルに表示する機能も備えた、文書情報専用の多次元分析ツールである。昨年末の市場導入以来、国内のトップ企業で様々な活用(特許、サービス、技術、マーケティング情報等)が始まっているが、本研究会では、医療分野における有効性についてデモを交えてアピールしたい。
1.はじめに:情報マイニングとは?
昨年末より、情報マイニングと言う言葉が日本においても市民権を得つつある事は、多くの人々が認める所である。情報ネットワークが整備された今、誰しもが想像を越える莫大な情報量に簡単にアクセスできるようになり、それらを活用して膨大な情報の中からスピーディに対象文書を検索したり、新たな観点から関連する情報を抽出する事で、目前の業務に生かしたいと望んでいる。つまり、山のような情報の中から欲しいものを掘り出す(Mining:採鉱)作業が“情報マイニング”であり、それをサポートするのが“情報マイニングツール”であるが、その具体的な内容となると、いまいち明確な定義はないのが現状であろう。ここでは、簡便のため以下のような区分で議論をすすめたいと思う。
データマイニングについては、一昨年から昨年にかけて大いに脚光を浴び、データウェアハウスとして概念化されているが、現実の企業内情報の90%は文書情報である(注1)と言う点[石井1]からしても、“情報マイニング”こそが企業活動の根本であると考えられる。さらに、日本のトップ企業ではグループウェアを中核とする情報系への投資が、数年前から開始・継続された結果、企業内ネットワーク上を膨大な文書情報が飛び交う状況が実現しつつあり、様々な文書DBへのアクセスが日々の業務の中で重要な地位を占めつつある。
この様な状況の中で、昨年末に従来のキーワード検索から大きく進化した検索ソフトウェアが相次いで商品化(注2)され、注目を浴びているが、これらの動きは冒頭に述べた文書情報処理が今後のキー課題となる事を示していると考えられる。 そこで本稿では、当社が最近開発し市場導入したVextSearch(ベクストサーチ)のコンセプトと基本機能を中心に、“新しい潮流を目指した、新しいコンピュータ利用技術の展開“について解説したい。
2、従来の文書検索技術と問題点
これまでの文書検索と言えば“キーワード検索”であり、質問文として入力された単語の有無だけで、対象文書と質問との関連性を判断するものであった。この状況は、以前の固定キーワード方式でも最新のフリーキーワード(全文検索)方式でも全く変わっていない。検索技術に関するこれまでの技術的進展は主として量的なレベルであって、膨大な情報量を迅速に処理する点に限定されており、検索そのものの質的レベルでの本質的な機能向上は実現されていないと言うのが、我々の基本認識であり、その問題点は以下の2点である。
上記の観点から、数値DBと文書DBの様々な処理機能について比較してみると、表1に示す通り、数値DBに対しては様々な支援機能が実用化されているのに対し、文書DBでは以前からの“文字列検索”とそれを用いた“集合演算機能”しか実現されていない。これではスピーディかつ多角的な視点で情報検索したいという要求に答えられない事は明らかである。 しかし技術的には、この壁は極めて高い障壁であった。つまり、これまでは文章や言葉の世界における相互の関連性とは人間だけが定性的に判断できることとされ、コンピュータ処理で数値化できるとは考えられなかったからである。
| No | 処理機能 | 数値データベース | 文書データベース |
| 1 | 特定項目の抽出 | 文字列、数値の検索 | キーワード検索(検索文字列の部分適合も含む) |
| 2 | 集計・演算 | 行列、統計等の豊富な解析機能が提供されている。 | 集合演算(AND、OR、NOT)に限定される。 |
| 1)序列化 | Sorting機能として定着 | 十分な機能は開発されていない(キーワードの頻度情報による重要度付けが参考となる程度) | |
| 2)相関解析 | 重回帰を始め、多くの解析手法が提供されている。データマイニング゙ではニューロ技術により自動的に相関関係を抽出する手法が脚光を浴びている。 | 全く開発されていない。 | |
|
| 3)自動分類 | クラスタ分析、κ2乗検定等の統計手法を活用 | 全く開発されていない。 |
| 3 | 視覚化 | 2次元、3次元の多様なグラフ表示機能が標準装備。 | 全く開発されていない。 |
我々は、前述の問題点を解決して誰にでも簡単でしかも分かり易い情報検索を実現すべく、これまでにない全く新しい方法論でチャレンジし、その実用性をビジネスの現場で実証しつつあるので次にそれを紹介したい。
3.新技術の紹介
前述の様にキーワード検索は、質問されたキーワードと言う記号の有り無し情報しか扱っておらず、他に何らの知識も使っていない。従ってこれを越えるには人間が文書を検索・分類する際に、それまでに蓄積した広範な知識を活用するように、検索システム用の“新しい知識”が必要である。しかも、その知識は従来のシソーラスや関連語辞書のように人間が作るのではなく、システムが“自動学習”できないと変化の早いビジネス現場では有効に活用できないと考えられる。
ここで、前述した技術的障壁(=言葉や文章の関連度)について考えてみたい。
3-1 言葉の関連度について
これまで、文書あるいは言葉の関連性を判断するには、言葉の意味を理解する必要があると考えられてきた。つまり、関連性の判断とは言葉の意味を知る人間だけが為しうる高度な抽象化機能(=概念化)であるとされてきた。即ち、馬と牛の関連性を説明する為には足が4本とか蹄があるといった共通点の抽出が必要となるという主張であり、これは全く正しい。それと同時に勿論、現状のコンピュータ技術ではこのような抽象化機能は実現不可能である。
しかしながら、我々はここで難しい哲学論議をしようとするのではない。むしろ、子供から大人まで誰もが知っている簡単な事実に目を向けてみようと思う。例えば、次の様な連想ゲームである。
| 1)くしゃみ、鼻づまり、マスク、春先に多い、とくれば :スギ花粉症 |
上記の例なら、誰もが簡単に答える事ができるし、新聞記事を例にとれば、花粉症の記事には、くしゃみ、鼻づまり、マスクと言った言葉が満ち溢れ、O157の記事には病原性大腸菌、食中毒と言う言葉が多用されていることが経験的に納得できる。又、逆に花粉症の記事に、病原性大腸菌や食中毒と言った言葉は、まず登場しない。つまり、各々の記事はそれぞれに関連の高い語群で構成されていると言える。
これらは共起性(Co-Occurrence)と呼ばれ、全ての言語に普遍的に存在する性質の一つである。即ち、関連の高い言葉は、“互いの近傍に、しかも頻繁に出現する”性質を持つ。(注3)
そして、もう一つ重要なのは、上記の関連性(あるいは連想性)は我々にとって非常に明確であるが、日常生活の上で我々はそれらの関連性についての論理的裏付けをあまり意識せずに用いている点である。(例えば、花粉症とくしゃみの因果関係を説明するのは、かなり困難であろうと予想される。)つまり、冒頭で述べた様な“意味を理解する”事には幾つかの段階があり、その最上位レベルは論理的思考に基づいて事象を解釈する事であるが、最下位レベルでは単に関連の深い現象を想起するだけの“雰囲気的理解”が存在し、我々は日常的にそれらを柔軟に使い分けて、類推したり共通性を判断したりしているのである。
要は、一々理屈を知らなくとも関連の深い事柄さえ知っていれば、実生活で十分(?)役に立ってしまう事は疑いようのない事実である。(残念ながら、これが知ったかぶりの温床となっている!)これらの事は、次の2つの点を我々に示唆してくれると考えられる。
以上の観点に立てば、文書DBから連想ゲームの様に“言葉と言葉の関連度情報”を抽出し、それを情報マイニング用の“知識”として活用すれば、究極の目標である概念検索に大きく近づける可能性が見えてくる。
そしてこのような“言葉と言葉の関連度情報”(以下これを“知識”と呼ぶ)を、人手を全く介さずに解析するのが、我々の提供する“新情報マイニングツール:VextSearch”である。
3-2 新技術の特長
前章での論点をベースとすれば、ここで紹介する多次元ベクトルによる情報検索手法は理解し易いだろうと思われる。この新手法は、本章の冒頭で挙げた2つの技術課題(検索用知識とその自動学習)を同時に実現した画期的な技術であり、米国のベンチャー企業であるAptex社及びその親会社であるHNC社により、1994年に開発された。(注4)
その特長は、検索に必要な知識は文書データベース内に存在していると言う新しい視点であり、その“知識”を最新の自然言語処理技術とニューロ技術で抽出するものである。勿論、この技術の最大の成果は言葉と言葉の関連度を数値化したことであり、そのポイントは以下の3点である。
1)ある事象に関する知識(前述の“雰囲気的理解”のレベル)は、それと関連の深い語群から成り立っており、連想ゲームに似ている。
| 例: たまごっち : ペット、ゲーム、携帯型 |
この“言葉と言葉の関連度情報”を検索用の“知識”として用いる事で、概念的な検索・分類が可能となる。
2)この“知識”は、文書DB内での言葉の共起性に基づいて抽出でき、本システムでは“多次元空間でのニューロによる学習システム”により、コンピュータが自動学習する。
3)各単語は多次元ベクトル空間上(約300次元)に配置され、類似する言葉は同じ方向を向く様に学習が進み、ひとつの集合を形成する様になる。各々の集合は、上記の連想クイズの様に互いに関連の深い語群から成り立っており、ある概念に対応している。スポーツ
一例として、新聞記事(1年間分:130MB)の場合を取り上げると、本システムは、そこに出現する約10万語(名詞、動詞、形容詞等)間の関連度を学習することになる。
そのプロセスは、表2の様なアナロジーでイメージすると理解し易い。つまり、広大な宇宙空間の中で、初めは均等に分布していた星(=単語)が、関連の高いもの同士で多く集まって銀河(=分野)を形成してゆく過程に似ている。
| 区分 | 単語 | 概念 | 分野 | 全コーパス |
| 例 | 投手 | 野球 | スポーツ | 文書全体 |
| アナロジー | 星 | 太陽系 | 銀河 | 全宇宙 |
<初期状態> <野球記事で学習> <アウトドアの記事で学習>
図2.本システムの学習プロセス
本システムの学習過程(図2)では自動的にインプットされる学習文書を、まず形態素解析により各単語に区分し、助詞や接続詞等の不要な語を除去する。次に各々の文書内での各単語の共起性に基づいて、関連の高い単語同士が同じ方向を向く様に、序々に学習が進み、その集積された結果として星雲の様な濃淡を生ずるものである。
この意味で、本システムの単語ベクトルを“ContextVector”と呼んでいる。一例として、本システムが学習した関連度情報を表3に示す。共起性に基づいて判断された言葉の関連度が、様々な分野のコーパスにおいて、適切な結果をもたらしている事が解る。
| 学習コーパス | コンピュータ情報誌 | 特許情報 | 新聞記事 | |||
| 対象語 | エレクトロニックコマース | トランジスタ | 育児 | |||
|
| 関連語 | 関連度 | 関連語 | 関連度 | 関連語 | 関連度 |
| 1 | 商取引 | 74.0 | ラテラル | 81.0 | 休業 | 61.0 |
| 2 | EC | 70.0 | マルチエミッタ | 80.8 | 家事 | 49.0 |
| 3 | 電子 | 58.0 | PNP | 80.1 | 無給 | 46.0 |
| 4 | コマース | 43.0 | NPN | 78.9 | 出産 | 46.0 |
| 5 | インターネット | 42.0 | コレクタ | 75.1 | 養育 | 39.0 |
図3. システム構成<<簡単入力>>
本システムではキーワード検索とは異なり、質問語の選定に注意を払う必要はない。似たような表現であれば、システムがフォローしてくれるし、質問語句が多い程その意図に近い文書を探し出してくれるので、ユーザーは自然文で思い付いたままどんどん入力するだけで良い。
<<一目で判断>>
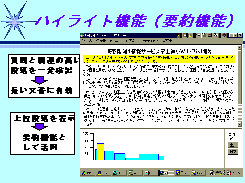
結果は、質問との関連度の高い順に出力される(Sorting機能)ため、検索の上位だけをチェックすれば良く、すぐに結果がわかる。これまでの経験では、新聞記事の場合で90%の確率でTop3に目的の文書が存在する。
<<類似文書も一発検索>>
本システムのユニークな活用として類似文書検索機能がある。これは、サンプルとなる文書全体やパラグラフを質問文とする(選択ボタンを押すだけ)ことで、それに類似する文書を極めて容易に検索するもので、利用範囲の広い新機能である。現実問題として、検索する際に最も煩わしいのは質問文を考える事であり、本機能を使えば、最初の曖昧な質問で検索された上位の文書で希望に近いものを選択し、次にその文書全体を質問にして検索する事で、非常に簡単に欲しい文書群をまとめて検索できる。
4-2.検索の事例
ここでは、類義語を含めた検索を実現している事例として“ヤワラチャンの復帰についての記事”についての検索結果を図4に示す。検索結果の上位5位(表A~E)を示すが、全て田村亮子選手の復帰試合に関するものである。ここで注目して欲しいのは、第1位と第2位には“ヤワラチャン”が載っているが、第3位以降には“ヤワラチャン”でなく“田村亮子”としか記載されていない。これは本システムが、“ヤワラチャン”と“田村亮子”が非常に密接なものであると自動学習した為に、このような検索結果が得られたのであり、通常のキーワード検索では同義・類義語として設定しない限り実現不可能なものである。実際、システム内での“ヤワラチャン”と関連の高い言葉をリストアップすると、表Fの様になる。
|
|
| |||
|
|
|
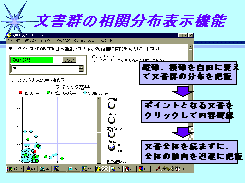
4-3.自動分類機能(Clustering)
前章で解説した“文書を概念的に把握する機能”は、検索だけでなく分類機能にも非常に有効であり、むしろ分類と言う“非常に曖昧で、きちんと定義しにくい知的作業”にこそ、その真価が発揮されると言って良い。その効果は次の2点で代表される。
本機能は任意の文書群に対して、指定した数の集合(Cluster)に自動分類するもので、分類結果と共にその集合の代表語が抽出される。表4は、新聞記事を対象にして[流行]と質問した際に検索された上位100件に対し、3グループに分ける様、指示した結果である。ここでは、夫々の記事内容は割愛するが、代表語を見ただけでもほぼ妥当な分類結果である事が推定できると思われる。
さらに別な分類方法として、事前に各グループのサンプル文書を教示データとして与えた上で、自動分類させる機能(Categorization)も同様の技術をベースに製品化(商品名:Convectis)されている。
| 質問:「流行」の検索結果の上位100件のクラスタリング結果 | |||
| Gr | 代表語 | 件数 | 内容 |
| 1 | ワンピース、スカーフ、光沢、ブーツ、おしゃれ、サンダル、体形、愛用、水着 | 62 | ファッション関係の流行に関する記事 |
| 2 | 巨匠、ピカソ、オブジェ、名作、サーカス、批評、短歌、写真集、オリジナリティ | 21 | 芸術関係の流行に関する記事 |
| 3 | 流行、あてはまり、キルト、思考、感性、クリック、団塊、サーフィン | 17 | 流行の捉え方等に関する記事 |
|
|
|
| | |
| |
| ||
|
|
|
6.今後の展開
以上の様に、我々の提案する多次元ベクトル手法は、従来のキーワード検索を遥かに超える新次元を切り開くものであり、人間の持つ言語処理機能に一歩近づく大きな進化であると考えられる。又、自然言語処理の急速な発展により構文解析等の技術が高度化すれば、より深いレベルからの関連度抽出が可能となり、本来の知識に迫る事も夢ではなくなる。
“VextSearch”の提供する様々な機能と可能性について、多くの方々からの忌憚のない御意見と新しい活用方法についての御提案をお願いする次第である。
7.参考文献
注1) コンピュートピア、1997-7、P71
注2) 日経コンピュータ 1997-12 P154、日経エレクトロニクス 1997-12P63, 月刊アスキーー 1998-5、Vol.22, No.5, P194
注3) W. R. Caid and J. L. Carleton, " Context Vector-Based TextRetrieval",IEEE Dual-Use Conference, 1994
注4) Robert Hecht-Nielsen," Context Vectors", IEEE World Congresson Computational Intelligence ,1994
| コマツソフト株式会社 情報マイニング事業室 石井 哲 〒113-0034 東京都文京区湯島2-31-22、TEL:03-5689-8105 FAX:03-5689-8154 E-mail: tetsu_ishii@komatsusoft.co.jp URL: http://www.komatsusoft.co.jp |