1. はじめに
XMLはメタ言語としての性質を持っている。つまりXMLはそれ自身で様々な用途に特化したマークアップ言語を定義できる。これによる最大のメリットはデータの再利用性を高められるという事であろう。これには2つの側面がある。一つはDTDの標準化によりデータの交換が容易になるという面であり、MMLはその一例である。もう一つはXMLで記述された文書それ自体がデータベースと成り得るという面である。高性能な検索機能を持てば、XMLで記述された電子カルテシステム全体があたかも巨大なデータベースのように機能する。
そのような検索機能の実現は電子カルテのデータとしての価値を高め、電子カルテシステムの普及と利用率向上に役立つと考える。
2. XML検索システムに求められる機能
2.1 TAGを意識した検索山田太郎という患者のカルテを検索する場合、患者氏名を表すTAG内に"山田太郎"という文字列を持つカルテのみがヒットすれば良く、山田太郎医師の書いたカルテや、山田太郎さんを父親に持つ患者のカルテはヒットしない事が望ましい。XMLの特性を活かして効率的な検索を行うにはTAGと文字列の組での検索が必須であると考える。
さらに効率的な検索を行うためには、文字列の『前方一致』『後方一致』『部分一致』の他に、自然言語を検索する場合は文字間の空白や些細な違いを無視した『曖昧検索』、数値データの『大小比較』や『近似値』検索等の実現が望まれる。
応用としては、<文書種別>が"退院時サマリ"で<最終診断名>に"肺上皮癌"という文字を含み、<退院日>が"1998年以降"のカルテを検索する等という事が考えられる。
2.2 TAGの追加に対応可能な柔軟性
現在電子カルテは黎明期にあると考えられ、特定の文書や特定の診療科のみで電子カルテを試行し、順次適用範囲を拡大していくという導入手法が多く見られる。コンピュータシステム上は新たなDTDやスキーマが発生するという事になる。また長期的には医療の変遷によって新たなTAGが発生する可能性は高いと考えられる。
したがって新たな文書やTAGが追加されても、アプリケーションの修正や、データベースの再構築が不要な柔軟性を持つ事が望ましい。
2.3 大量データの検索性能
検索対象となる文書は膨大な数になる事が予想される。1回の記録単位を1文書として計算した場合、大学病院規模であれば5年間で1千万件を超えるであろうと試算している。これ程の件数を実用的な速度で検索するには効率的なIndexが必須であろう。検索の度に文書の実体を検索していたのでは満足できる性能を出す事は難しい。
3. 既存の技術の評価
3.1 全文検索システム一口に全文検索システムと言っても検索のロジックはそれぞれ独自の方法であるが、一般的には検索の適合度を判断するのに字句の登場回数や登場した位置等を使用している。検索用のIndexが文書の構造やTAGを意識していない為、新たな文書やTAGが発生しても設計変更が不要な点が長所である。
しかし上記の長所がそのまま欠点にもなる。TAGを意識した検索を行う事は不可能であるため、特定のTAGと値をダイレクトに指定した検索を行う事ができない。検索精度には自ずと限界があり、目的のデータに辿り着くまでに何度も絞込みを行う事になる。
3.2 データベース(RDB)
特定のデータ構造にマッチしたインデックスを作成する事が可能であり、想定した範囲内であれば高速な検索が期待できる。最近見られるXMLをRDBの複数のテーブルにマッピングする技術を使えば、これまでアプリケーション開発のネックであった、RDBでXMLの階層構造を扱う事の難しさからは逃れる事ができる。
しかしスキーマが固定されるため拡張性に難があり、設計時に想定したパターン以外のデータを格納・検索する事はできない。稼動後にアプリケーションやデータベースの設計変更を行う事は可能な限り避けたい所である。
3.3 XQL
XMLの検索言語としてW3CのXSLワーキンググループによって定められたXQLがある。XML専用の設計であり、文書の構造やTAGを意識した完全な検索を行う事ができる。また検索の自由度も高い。
しかし現在の実装ではDOMを使用して文書毎に検索する仕様であるため、複数の文書を串刺しで検索する場合はプログラム的な工夫が必要である。またIndexを使わない仕様であるため、性能面では全く期待できない。
※最近XML対応を謳ったデータベース製品がいくつか発表されている。残念ながらまだ実際に使った事がないため個々の製品の機能についてはコメントできないが、上記の拡張性と性能の問題が解決されているのであれば期待が持てる。
以上の内容をまとめてみると、『全文検索エンジンの柔軟性』『データベースの性能』『XQLのヒット率』を満たせばXMLの検索エンジンとして満足できる物となろう。
このような条件を満たす検索エンジンを検討した結果、現時点では通常のデータベースや全文検索システムを使用する事は難しいと判断し、インターネットディレクトリ技術として注目を集めつつあるLDAPを使った検索システムを考案した。
4. LDAPとは?
Lightweight Directory Access Protocolの略で、インターネットディレクトリを利用するためのプロトコルとしてIETFにより開発されたオープンなインターネット標準規格でありRFC1777と1778で定義されている。(LDAPv3はRFC2251~2256)LDAPは元々X.500 Directory Serviceのフロントエンドとして開発された物であるが、現在では完全にスタンドアローンなディレクトリサーバとして機能する。X.500とLDAPの関係はSGMLとXMLの関係に似ており、上位規格の10%の労力で主要な90%の機能を実現する事ができるよう設計されている。
サーバ製品は富士通をはじめ、NetscapeやSun、Oracleその他大手ベンダより発売されている。多くの製品がマルチプラットホームに対応しており、主要な商用UNIX、WindowsNT、Linux上で動作する。オープンソースのプロダクトとしてOpenLDAPがある。最近ではWindwos2000に搭載されたActiveDirectoryもLDAPを採用している。クライアント側は既にInternet ExplorerやNetscape Navigatorに搭載されている。
LDAPを使用した事例としては、NetscapeのOpenDerectoryプロジェクトや日経BPのFind'Xで、Webページをディレクトリを使って分類、検索するサービスを提供している。またCNN.COMではユーザのプロファイルをディレクトリを使って管理し、ユーザに合ったバナー広告を表示している。
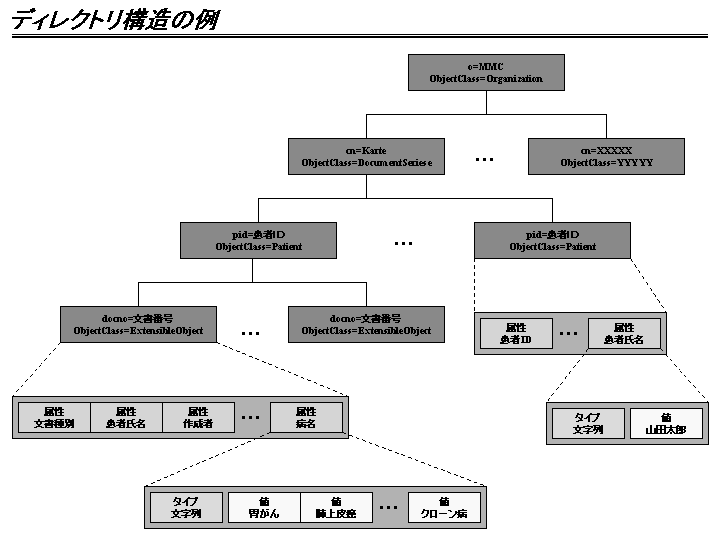
ディレクトリとは所謂フォルダの意味ではなく、英語本来の『登録簿』的な意味である。エントリ(電子カルテでは患者やカルテに相当)とその属性(氏名や病名を表すTAGに相当)の組を階層構造で持つことができる。各属性は複数の値(氏名や病名に相当)を持つ事ができ、属性と値の組により検索する事ができる。検索条件としては"前方一致"、"後方一致"、"部分一致"、"近似値"、"大小比較"等が予め準備されており、これらの条件を組み合わせて検索を行う事が可能である。⇒高いヒット率が期待できる
この条件式(フィルタ)もRFC1960で定義された標準規格である。
各エントリがどのような属性を持つかはオブジェクトクラスにより定義されるが、ExtensibleObjectクラスを使用すれば任意の属性を持つ事ができる。すなわち設計時に想定していなかったTAGも属性として格納できる。高速な検索を行う為には属性毎にIndexを作成する必要があるが、これも多くの商用LDAPサーバではシステム稼動中に動的に追加する事が可能である。⇒柔軟性が高い
LDAPはトランザクション処理を持っていない。したがって更新系の機能は貧弱であり基幹系のシステムに適用するのは難しいが、その軽量故に動作は非常に高速である。Mindcraft社のベンチマークテストによると、Netscape Directoryサーバの場合PentiumPro 200MHzクラスのサーバで183件/秒の検索性能を出している。(エントリ数が1万件の場合)
実際に我々が行ったベンチマークでは、Pentium 200MHzクラスのサーバで、100万件のデータから10件を検索するのに5秒以下であった。⇒検索性能が高い
5. 実装
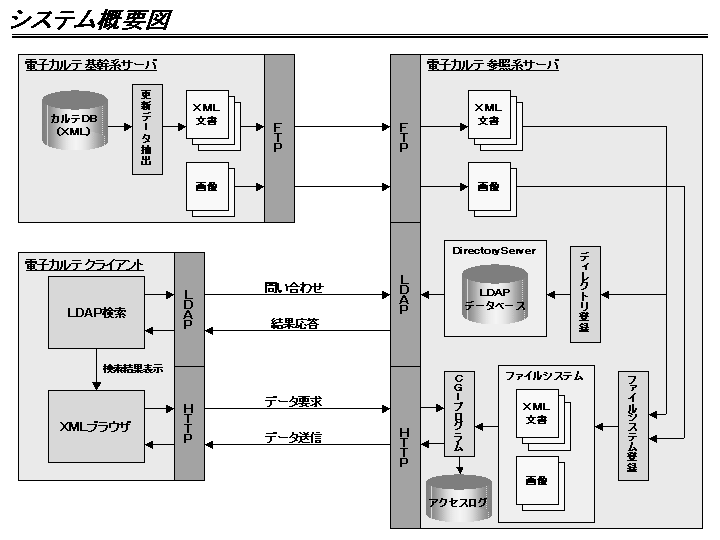
XML文書全体をLDAPのツリー構造にマッピングさせて格納し、参照時に再構築する事も可能ではあるが今回はその様な手法は採用していない。カルテ(XML文書)の実体は完全な形の文書として存在する必要が有るため、LDAPで文書構造を表現する必要は無いと考えたからである。文書構造を表現する為にはXML文書内の各エレメントをLDAPエントリとして登録する必要があるため、検索の性能面でもデータ容量面でも不利である。LDAPはXML文書の実体へのポインタとして使用している。クライアントはカスタムアプリケーションを作成した。複雑な検索フィルタの入力補助や非同期検索、検索結果のソーティング等の機能が必須であると判断したからである。またXML文書の表示にはスタイルシート(XSL)を使用し、参照時に任意のスタイルシートを選択する事を可能としている。
検索処理自体はLDAP検索フィルタ(RFC1960)を発行するだけであるため、LDAPサーバの種類に依存しない。実際にOpenLDAP、Netscape Directoryサーバ、InfoDirectoryを使用して互換性テストを行ったが、どのサーバを使用しても同じ結果を得る事ができた。
サーバ側でXML文書をLDAPに登録する機能は、DOMを使用した汎用的な物としている。基幹系システムで入力されたXML文書をパースし、該当する患者のエントリが無ければ新規に患者エントリを追加する。その後患者エントリの下に文書のエントリを追加し、文書内のTAGを文書エントリの属性として、TAG内の文字列を属性の値として格納する。
LDAPツリーにXML文書のエントリを登録するルールさえ決まれば、どのようなXML文書であれLDAPに登録する事ができる。したがって電子カルテに留まらず様々なXML文書の検索に応用する事が可能であると考える。
6. 考察
昨年から『ヒット率』『検索性能』『柔軟性』という3点をキーワードにいくつかのXML文書の検索手法を模索した。当初LDAPはその選択肢の一つに過ぎなかったが、実際にプロトタイプを作成して評価した結果、文書の検索に非常に有効であった。人気Webサイトで、LDAPを使った分類、検索サービスを行い出した事はその証明であろう。現時点ではアプリケーション開発環境が充分とは言えないが、『機能』『標準』といった面で他の手法より有利であると考える。
参考文献
『XML開発事例 エレクトロニックコマース(XML by Example:Building E-Commerce Applicatons)』(著者:Sean McGrath / 発行:アスキー出版局)『LDAPインターネット ディレクトリ アプリケーション プログラミング(LDAP:Programming Directory-Enabled Applications with Lightweight Directory Access Protocol)』(著者:Tim Hows、Mark Smith / 発行:プレンティスホール出版)
Mindcraft Benchmarks Reports : http://www.mindcraft.com/perfreports/ldap/netscape/dirserver10.html