【はじめに】
株式会社アドバンスト・メディアは電子カルテに特化した音声認識システム「AmiVoice Medical」の開発を進めています。2001年10月より放射線科画像診断に特化した音声認識システム「AmiVoice Medical for Radiology」、病理診断に特化した「AmiVoice Medical for Pathology」の販売を開始し、2002年4月時点での導入稼動施設は15ヶ所となり我が国でも音声認識を利用した医療レポートの作成が本格的に始まりつつあります。
また、昨年度のMEDIS-DCによる「先進的情報技術活用型医療機関等ネットワーク化推進事業 」「岡山市立市民病院を中心とした地域医療情報化の推進」におきましても岡山市立市民病院様とのコンソーシアムに参加させていただき、脳神経外科、皮膚科の手術記録、診療情報提供書に特化した病診連携電子カルテシステム用AmiVoiceの開発を行いました。
今回はこれらの製品や成果物をデモンストレーションをまじえてご紹介させていただくとともに、部門システムだけでなく、あらゆる電子カルテシステムに適用した音声認識システム開発の今後についてご説明させていただきます。
|
|
|
|
(図1)クリックで拡大 |
(図2) |


【AmiVoiceの特長】
音声認識エンジン AmiVoice は事前に声の登録が一切不要であり、ユーザごとの声の質や、イントネーション、アクセントの違いはAmiVoiceが吸収しています。また領域を特化することにより認識率は95%以上を実現しています。
1.事前の音声による学習、トレーニングが一切いらない
2.高精度の認識率&認識処理スピードが速い
3.イントネーション、アクセント、発話スピードの変化に強い
4.実環境としてのノイズに強い
【AmiVoiceの構成】
□AmiVoice エンジン
音声認識のコア部分でフロントエンドと認識デコーダーによって構成されます。フロントエンドでは、入力音声から特徴量を抽出する前処理を行い、認識デコーダーでは、特徴量から音響モデル、辞書、言語モデルとのマッチングを行い、文字列に変換します。代理店向けの開発パッケージではこれらのコア部分をアプリケーションに実装するためにJava,C++,VBocxのAPIを用意しています。
□フロントエンド(Front End)
16kHz,16bitのサンプリングレートで取得した音声データをこのフロントエンドにて特徴ベクトルデータに変換します。データの容量はおよそ20分の1〜100分の1にまで軽減されますのでフロントエンド部分だけ独立チップ化させPDAや携帯電話端末に組み込むことによりサーバクライアント型の音声認識システムにおいて音声のネットワーク転送や電話回線でのサンプリングレート制限(8kHz,8bit)など伝送経路の帯域幅に左右されない高精度なシステムが構築可能になります。
□音響モデル(Acoustic Model)
フロントエンドにより変換された特徴ベクトルがどのような音素で構成されているかを推定するための確率統計モデル。AmiVoice では連続する3つの音素の出現確率(Triphoneをベースにしています。AmiVoiceの事前学習が必要ない完全不特定話者の特長はこの部分の実装方法によるものです。
□辞書(Dictionary)
単語と読み方のデータ。一般語のほかに個別の分野ごとに専門用語などを登録させます。
一般的に現在の音声認識技術では認識変換速度や認識単語の母数拡大による精度低減などの理由で約10万語の登録が上限とされており、それを超える場合は分野や運用ごとに辞書をセグメントして切り替える必要があります。たとえば日本人の氏名だけでも数十万語になるといわれておりますので、患者氏名や住所、薬品名、病名などはそれぞれ辞書を使い分けることになります。
□言語モデル(Language Model)
各単語がどのような文脈で出現するかを推定するための確率統計モデル(文法)。
AmiVoice では連続する3つの単語の出現確率(Trigram)をベースにしています。大量のテキストデータを学習させて開発します。学習テキストに出てくる専門用語や言い回しのバリエーションが認識精度に影響します。辞書と同じく分野が広いと認識母数が多くなり速度が遅くなります。また、文体が限定的な文章ほど文法の自由度が小さくなるので、より少量の学習テキストで認識精度の高い音声認識エンジンを構築可能になります。しかし、くだけた表現や口語、日常会話などになりますと単語の倒置や主語の省略、不要語の多発など、文法そのものの法則性が失われてしまうため高精度の認識エンジンの開発は困難であるといわれています。日本語音声認識システムの難易度の高さは、日本語口語の文法が曖昧であることが原因の一つです。
□認識デコーダ(Decoder)
AmiVoiceのコア中のコアで上記の音響モデル、辞書、言語モデルから認識単語を確定する演算を行う部分。
確率統計モデルから最適な値を算出する、隠れマルコフモデルといわれるアルゴリズムを応用することにより音響モデル、辞書、言語モデルから横断的に検索し最適な単語を確定させます。AmiVoiceでは認識途中のデータも取得可能ですので変換単語の候補列や音声と変換単語のタイムスタンプ情報などもアプリケーション側で利用可能です。
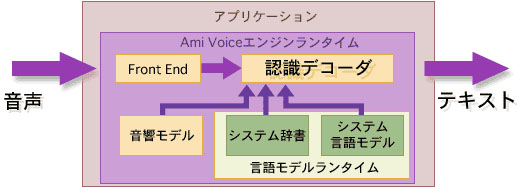
(図3)
【医療用の言語モデル/辞書開発】
・ 放射線科画像診断(AmiVoice Medical for Radiology)
単純X線/CT/MRI/RIの所見レポートの単語を約35,000語登録した放射線科向けの読影レポート用音声認識システム。音声認識率は平均97.3%(単語ベース*1)で1レポート平均200文字、平均単語長2.9文字として1レポート中に誤認識は 約2単語(個所)ということになります。本システム標準でも95%以上の高い認識率を実現しておりますが、病院側に過去の所見テキストが大量に存在する場合は それらを学習させカスタムオーダーメイドすることにより病院ごとの検査、略語、微妙な言い回しの違いも完全に対応させることが可能です。
・病理画像診断(AmiVoice Medical for Pathology)
・脳神経外科手術記録、診療情報提供書
・皮膚科手術記録、診療情報提供書
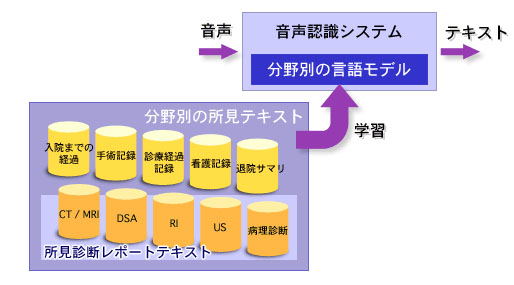
(図4)
【その他の応用】
・電話による診療予約システム
・薬品名
・病名
・患者名
・住所
株式会社アドバンスト・メディア(Advaned Media, Inc.)
〒170-6048
東京都豊島区東池袋3-1-1サンシャイン60 48F
Tel:03-5958-1091
Fax:03-5958-1033
URL:http://www.advanced-media.co.jp
音声認識.jp
E-mail:kishi@advanced-media.co.jp